前几天在 bilibili 上看了一个 up 主的埃及旅游系列 vlog,了解了一些关于古埃及历史的知识,再通过维基什么学习,写下本文以做笔记。本文基本来源中英文维基,英文为主中文为辅,精简了大量不太重要的细节,比较适合快速了解和学习古埃及历史。如果对内容有什么疑问或者质疑,请务必留下评论或者联系我做讨论。
综述
时间上只会覆盖到中世纪之前,个人认为古埃及在阿拉伯人入侵之后就算是玩完了,所以之后的时期不做记录。
首先,整个古埃及基本就是沿着尼罗河建立的。尼罗河的走向是自南向北,古埃及也经常因为统治的原因,一段时期分成上埃及和下埃及,一段时期则是统一,正所谓分久必合,合久必分。上埃及是在南边即上游,而下埃及则是在北边即下游。
埃及学者一般根据托勒密王朝早期古埃及祭祀曼涅托的《埃及史》将古埃及历史分成八到九个时期,三十一个王朝(一个王朝不一定只有一位法老),而古埃及人则似乎是不划分历史时期的。另外考古出来的历史也各国不一,这里以维基为准。
这几个时期分别是前王朝时期、早王朝时期、古王国时期、第一中间期、中王国时期、第二中间期、新王国时期、第三中间期和古埃及后期。实际并不需要将所有的时期都记得一清二楚,只需要记得一些时期和王朝比较有名的事件和法老即可。
另外古埃及到了第三中间期之后的后期,已经无力回天,被外族来回入侵,再之后又来了马其顿和罗马,最后被阿拉伯完全控制后到现在基本就已经是一个穆斯林国家了。
古埃及年表在时间上的认定也不一,相差会有几十年,不过其开始一般都在 BC(before century,公元前)3100 左右。
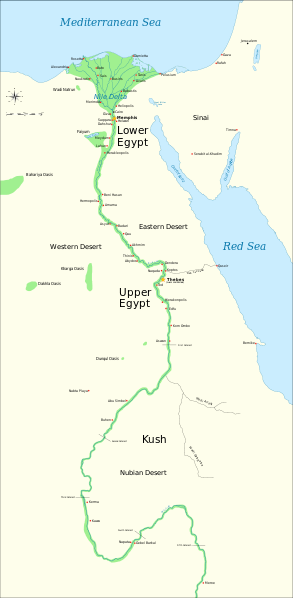
前王朝时期(BC3100 之前)
经历了旧石器时代和新石器时代,大概 BC3600 年开始,尼罗河沿岸出现几十个「诺姆」,相互各自斗争。
诺姆:nome,源自希腊语 Νομός,意为 “行政区”;埃及语:Gau,中译「州」。
早王朝时期(Early dynastic period, BC3100 - BC2686)
第一王朝建立者,美尼斯
传说中美尼斯(Menes)统一了上下埃及开创古埃及王朝。但从考古证据上则很难支持有这么一个人,反而认为是纳尔迈(Narmer)才是统一埃及第一人,或者说两者是同一个。
包含一至二王朝,两个王朝,2 / 31。
古王国时期(Old Kingdom, BC2686 - BC2181)
第一个建造金字塔,左塞王
现在看到的著名金字塔基本就在这个时期被建造。
此时期第一个法老(pharaoh)左塞王(King Djoser)开始建造阶梯金字塔(最常见最有名那种),位置在萨卡拉(开罗以南约 30 公里)。
阶梯金字塔据说是是伊姆霍特普(Imhotep)设计的。
伊姆霍特普,出身平民,但因智慧过人,学识渊博,受到法老的破格重用。他在整个法老时代受到崇拜,死后被尊为神,名号被刻在法老左塞雕像的基座上。…… 古埃及医学的奠基人…… 被誉为历史上第一位留下姓名的建筑师与医师,被奉为医学之神
维基百科
甚至有伊姆霍特普博物馆,见 维基,egyptsites 博客。

最大的金字塔,胡夫金字塔
胡夫是第四王朝的第二位法老,是首位在吉萨建造金字塔的法老。今天去埃及旅游看的三座大金字塔就在吉萨,其中最大的就是胡夫下令修建。
胡夫金字塔塔高大概 146.5 米,现为大概 137 米,边长接近 230 米,由 230 万块巨石搭建而成,最重的可达 50 吨,最小的也有 1.5 吨。
胡夫金字塔是古代世界七大奇迹中最为古老和唯一尚存的建筑物。
有一个入口,但是现在被封禁,只使用某位哈里发在 CE820 开凿的盗墓通道作为入口。
尽管建造了最大的金字塔,但胡夫本人的雕像却是考古发掘中所有法老雕像中最小的。

第二大金字塔,卡夫拉金字塔
卡夫拉是胡夫的孙子。尽管看起来卡夫拉金字塔比胡夫金字塔小一点,但是卡夫拉金字塔底座更高了 10 米,塔周边也更多附属设施。
狮身人面像斯芬克斯就属于附近的建筑,但并不是问路人问题杀人那只。


孟卡拉金字塔
孟卡拉是第四王朝时期的第 16 位法老,孟卡拉金字塔远小于前两座金字塔,它的高度只有大约 65 米,总体积大约只有卡夫拉金字塔 1/10。
萨拉丁的儿子奥斯曼曾试图拆除孟卡拉金字塔,最后太过困难而作罢,给金字塔北面留下很大的垂直裂缝。


包含三至六王朝,四个王朝,6 / 31。
古王国时期后期出现严重干旱,国力下降,封建制度也削弱了中央权利,出现第一个黑暗时期,极其混乱的一个时期。这个时期法老权力被极度削弱,地方官员权利变大,在自己领地几乎就成了法老。
七八王朝极度混乱,史书记录不清。
曼图霍特普二世(Mentuhotep II)重新统一
古埃及也分成了上下埃及,下埃及经历九十两个王朝,上埃及则是十和十一王朝。最终上埃及由曼图霍特普二世(Mentuhotep II)向北进攻击败下埃及统治者再次统一古埃及,并继续主持十一王朝,进入中王国时期。
经历大概第七王朝到第十王朝,四个王朝,10 / 31。
中王国时期(Middle Kingdom, BC2030 - BC1650)
十一王朝再次统一之后,开始重新收复失地,包括南边曾经在古王国和中间时期失落给努比亚的土地。
努比亚相当于今天埃及和苏丹交界位置。
十二王朝迁都底比斯(今卢克索)。
塞索斯特利斯三世(Sesostris III)扩张到努比亚
塞索斯特利斯三世(Sesostris III)是十二王朝法老,善战,向努比亚扩张,然后还建造了很多堡垒,被认为是这个王朝最强大的法老。
之后他的儿子阿蒙涅姆赫特三世(Amenemhat III)的统治时期被认为是中王国时期经济最好的时期。不过他从西亚邀请了希克索人(Hyksos)到尼罗河下游三角洲定居,也给后面十三十四王朝的结束埋下了隐患。其实十二王朝末期尼罗河洪水减少也为国家带来打击。
第一位可考的女法老,塞贝克涅弗鲁(Sobekneferu)
阿蒙涅姆赫特四世(Amenemhat IV)去世后,其子年幼,于是其姐妹塞贝克涅弗鲁(Sobekneferu)成为了历史考证上第一位女法老。她在位三年后去世,政权持续衰弱,是十二王朝最后的法老。
奥西里斯在这个时期成为了最重要的神。
经历十一王朝到十三王朝,三个王朝,13 / 31。
十三王朝的继续衰弱导致尼罗河三角洲(属于下埃及)的政权脱离并独立,是为十四王朝。统治者可能是迦南人(闪米特人)血统。
注意十三王朝和十四王朝几乎是共存的,直到 BC1650 希克索人全面控制下埃及,攻占了古首都孟菲斯。
希克索人的外族统治
希克索人对下埃及的统治被视为十五王朝,而南边的底比斯统治者也趁十三王朝的真空宣布独立并宣布十六王朝。
希克索人继续南下把十六王朝打败后,北退,上埃及建立十七王朝与希克索共存。
十七王朝学习希克索人的战术和武器,在十七王朝最后两个法老统治期间反攻北面希克索人。
阿赫摩斯一世(Ahmose I)是十七王朝最后一个法老的弟弟,继续父亲和兄长意志将希克索人赶出埃及,开创十八王朝,进入新王国时期。
包含十四王朝到十七王朝,共四个王朝,17 / 31。
新王国时期(New Kingdom, BC1570 - BC1070)
这个时期有很多有名的法老。宗教上也有不少的变动。
在神明崇拜上,由于此时统一埃及十七王朝的统治者就是底比斯的家族,所以底比斯的地方神祇阿蒙(Amun)被推举到了主神的地位。由于古埃及一直以来一般都认为主神是太阳神拉(Ra),所以这段时期又经常将阿蒙和拉结合为同一个神,叫阿蒙-拉。
古埃及历史上最强盛的十八王朝就在这个时期内。
阿赫摩斯一世(Ahmose I)赶走外族,统一上下埃及
十八王朝第一任法老阿赫摩斯一世(Ahmose I),他登基的时候可能只有十岁,并可能在二十岁左右完成了「驱逐胡虏」,恢复了埃及对努比亚的统治。
之后是阿赫摩斯一世的儿子阿蒙霍特普一世(Amenhotep I)继位。
接下来的法老图特摩斯一世(Thutmose I)的身世则有点模糊,有可能是阿蒙霍特普一世的儿子,或者是他的军队指挥官。他意图扩大埃及版图,并第一个在帝王谷建造坟墓。

图特摩斯一世儿女中有一个儿子,图特摩斯二世(Thutmose II),是由妃子所生;其中有一个女儿,哈特谢普苏特(Hatshepsut),是由王后所生。
王后没有儿子,于是图特摩斯二世娶了他的姐姐哈特谢普苏特并登上王位,但很快就死了,而哈特谢普苏特只生了一个女儿,所以又从图特摩斯二世的妃子中找了个儿子当图特摩斯三世(Thutmose III)。
古埃及的「武则天」,哈特谢普苏特
或许是因为图特摩斯三世太幼小,又或者是因为哈特谢普苏特觉得自己是正统王室之后,因此虽然作为摄政王,但是肯定是想自己当甚至极有可能当上了法老。而且考古学者从资料和建筑中考据,亦基本承认了她法老的地位(同时图特摩斯三世仍然在位)。
哈特谢普苏特在位期间的贡献主要为重新建立被希克索人入侵时破坏的贸易路线,以及大兴土木建造了很多建筑。她停止了土地扩张,使埃及在叙利亚及巴勒斯坦的统治权动摇(死后更丢失了统治权,但后来图特摩斯三世重新收复),但加强了和邻国的贸易,使埃及变得富庶。
她在卡纳克神庙建造了两个方尖碑,其中之一是埃及现存方尖碑中最高的,约 29 米高。
她在曼图霍特普二世神庙旁建造的哈特谢普苏特神庙,是古埃及建筑杰作以及热门景区。




经历王女、王后、摄政王和法老,哈特谢普苏特让人联想起中国的「武则天」。
埃及的拿破仑,图特摩斯三世
图特摩斯三世在哈特谢普苏特统治二十一到二十二年后重新归来,并积极扩充军队和埃及版图,征服了地中海沿岸的以色列和叙利亚地区,甚至让邻国给其纳贡。图特摩斯三世也被后人称为「埃及的拿破仑」。
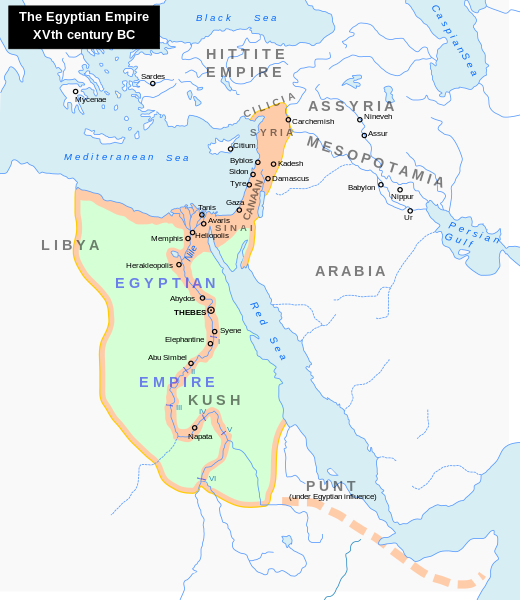
图特摩斯三世重获权力后,通过破坏纪念碑等方式极力抹除哈特谢普苏特的存在。后面的王朝在王表编纂上也似乎故意忽略了这个法老。
哈特谢普苏特和图特摩斯三世之间的关系,一般认为图特摩斯三世怨恨哈特谢普苏特。但最近一些研究进展称此说法不准确,并声称图特摩斯三世一直担当哈特谢普苏特的军事统治领袖,哈特谢普苏特也没有取其性命;而且损毁行动在图特摩斯三世统治晚期集中进行,哈特谢普苏特的资料也不是唯一被损毁的资料;从而推测图特摩斯三世是为了巩固继承人地位而作出如此的行为,他本人和他的继母并没有过节。这部分说法维基暂时没有找到证据支持。
埃及在图特摩斯三世以及几位法老的努力下,终于在阿蒙霍特普三世(Amenhotep III)治下达到艺术和国力顶峰。阿蒙霍特普三世一生建造了很多宏伟的建筑和雕像,其中有著名的门农巨像。门农巨像座落在是蒙霍特普三世神庙的门口守卫。而阿蒙霍特普三世神庙是埃及最大最华丽的建筑群,可是后来因为地震和被拆除的缘故,现在已经不存在了,剩下两尊残破的门农巨像。


帝国的强盛、对阿蒙神的崇拜和皇家经常修建神殿,令阿蒙神庙的祭司获得极大的财富和权力,祭司们不免出现腐败和干预朝政的行为。
被后继者视为异端的宗教改革者,阿蒙霍特普四世
于是阿蒙霍特普三世的儿子,阿蒙霍特普四世,相信是为了打击祭司和权贵,进行了宗教改革。他简化多神系统,要求全国改为崇拜唯一的太阳神阿顿(Aten),甚至把自己的名字改为阿肯那顿(Akhenaten),迁都埃赫塔顿(Akhetaten),摧毁阿蒙神庙。有学者认为这表明了他创造了世界上最早的一神教。但他沉迷新兴宗教事务,以至于对边疆情况置若罔闻,而此时地中海北面的赫梯人正值盛时。于是古埃及逐渐失去了西亚地区的影响力。
他的大皇后,娜芙蒂蒂(Nefertiti),很有可能和他一同统治埃及。

阿肯那顿的后继者在他死后又把旧宗教恢复回来,并大力抹消新兴宗教的记录和影响。

生前不出名,死后却最出名的法老,图坦卡蒙
阿肯那顿之后经过了一个或者两个短暂统治的法老(可能是他儿子或者王后摄政),王位传到了最著名的法老——图坦卡蒙(Tutankhamun)。

图坦卡蒙曾用名图坦卡顿(Tutankhaten),从名字的更改可以看出信仰的更改。他将首都迁回底比斯,重开神庙,重新恢复阿蒙神的崇拜。
图坦卡蒙的出名是因为所有法老的坟墓都几乎被盗空了,而唯有他在帝王谷的坟墓三千多年来从没被盗,以至于发掘出近五千件文物,令法老以及图坦卡蒙成为流行文化。
关于有名的「法老的诅咒」,可以说没有任何证据表明诅咒存在,坟墓内也没有发现任何诅咒的存在。打开坟墓和棺材的在场 58 人,据研究只有 8 - 10 人在十几年内死亡,根本不足为诅咒的依据。
2019 年(本年) 1 月,图坦卡蒙坟墓向游客开放。
混乱的最后几任十八王朝法老
然而图坦卡蒙似乎一直疾病缠身,18 岁就死了,死因有各种猜测,包括疟疾、腿疾或者被谋杀。他与其异母姐姐安克姗海娜曼的两个女儿也早年夭折,因此图特摩斯家族就绝后了。安克姗海娜曼似乎曾经写信给赫梯国王苏庇路里乌玛一世要求他要一个王子嫁给她,但是王子还没到就被杀了。
之后是阿肯那顿和图坦卡蒙大臣,甚至可能是其背后的操纵者,阿伊(Ay),极有可能娶了安克姗海娜曼,当上了法老,统治了一个很短暂的时期。之后就被图坦卡蒙的将军,霍朗赫布(又或者哈伦海布,Horemheb)夺取了法老位置。
霍朗赫布以孟菲斯为首都,继续抹除阿顿以及其前任等人的痕迹,算是个解决宗教动荡和国家分裂等麻烦的人。
霍朗赫布跟王室没有关系,也没有儿子,法老位置传给了当时的大臣门帕提拉(原名普拉美斯,Paramesse),即十九王朝的第一任法老拉美西斯一世(Ramesses I)。
被儿子盖住名声的塞提一世
拉美西斯一世的儿子塞提一世(Seti I)和她父亲重建了王国的秩序,并在叙利亚和迦南地区打击赫梯人的势力。从纪念碑上可以找到他的伟大功绩,虽然一般来说都是倾向于夸大。总的来说,塞提一世可以说是恢复新王国时期的荣光。
塞提一世也兴建了很多建筑,包括位于底比斯的塞提一世祭庙、位于阿拜多斯的塞提一世纪念庙以及大柱式大厅,虽然大部分应该是在拉美西斯二世时期完成的。

阿拜多斯的塞提一世纪念庙虽然外表其貌不扬,但是内部壁画精美,而且有不少壁画仍然有颜色。其中一面墙上按时间顺序记录了大多数王朝的法老的名字,从美尼斯到塞提一世共 76 个,被称为阿拜多斯王表,是后世研究历史的主要来源之一。




鼎鼎大名的拉美西斯二世
塞提一世的儿子就是赫赫有名的拉美西斯二世(Ramesses II)了。他如此的有名以至于后来有九位法老使用了拉美西斯这名字。他在位长达 66 到 67 年,执政的时期是新王国最后的强盛年代。
但凡古埃及强盛的时期,统治的法老无不是领土争端和宏伟建筑这两方面有所建树,拉美西斯二世也不例外。他打败从地中海入侵的海盗,向东北占领迦南地区和南叙利亚地区,和北面的强敌赫梯国王穆瓦塔利二世(Muwatalli II)来回地打拉锯战,最后分庭抗礼;稳定南边的努比亚。他在位时间比较长,也在埃及各地建造非常多的建筑,甚至在不是他建造的建筑上也留下标志。
卡迭石战役是埃及和赫梯之间比较著名的战役。战役的情况很可能是这样:埃及想进军占领卡迭石,但被赫梯战车袭击并击溃;法老在营地受困的时候雇佣兵到了,反击了赫梯,导致赫梯军败退;埃及虽然赢了这场战斗但是也无法攻克卡迭石,战略上算是输了。之后双方一直僵持不下。卡迭石战役有非常详细的记录,但基本都是埃及方面一面之词,因此也存在夸大拉美西斯二世的可能性。
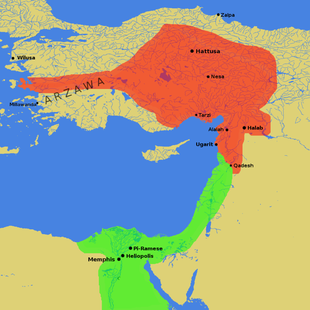
之后穆瓦塔利二世病逝,拉美西斯二世和继位的哈图西里三世(Hattusili III)缔结埃及赫梯和约,此时距离卡迭石战役已经十五六年了。
埃及赫梯和平条约,或称卡迭石条约、永恒条约、银条约,是古代近东(即今西亚、中东地区)地区协议双方都有保存下来的最古老的条约。缔结和约结束了长期的冷战实际上对签署双方都有利益。埃及的目的,很可能是为了吹嘘法老功绩,并成立军事同盟以共同对抗西亚更东边的新贵力量亚述;而赫梯的目的,则可能是新王为了巩固地位以及利用法老的国际影响力提升自己的国际地位。


拉美西斯二世的闻名也许也来自于他遍布埃及的大型建筑和到处刻画自己的荣光事迹。
比较有名的建筑是拉美西姆神庙、哈布城神庙和阿布辛贝勒神庙。
拉美西姆神庙现今已经是废墟,往日的样子只能靠门口和后面的建筑来想像了。


比较值得注意的是庙内有一副拉美西姆国王名单(Ramesseum king list),列出了新王朝的大部分法老。

哈布城神庙(Medinet Habu)离哈特谢普苏特神庙不远,很多法老都在这修建过建筑,刻过壁画。然而拉美西斯二世应该是其中最张扬的了,似乎很害怕被人遗忘。

拉美西斯二世本身就喜欢乱改别人的壁画,因此他也害怕别人抹掉他的壁画,于是他的壁画都刻得非常深。

阿布辛贝勒神庙(Abu Simbel temples)应该是很多人从电视媒体等看到过的神庙之一,整个神庙在岩石上开凿而成,门口四个雕像也是其标志之一。

神庙东北面是法老为哈索尔(Hathor,古埃及女神)和妮菲塔莉(Nefertari,拉美西斯二世的大王后)所建的小庙(the Small Temple)。妮菲塔莉的雕像跟拉美西斯二世一样高,表明地位跟他几乎平起平坐,也是几乎唯一一位在世就被神格化的埃及王后。其他同样有名的王后是克利奥帕特拉七世(埃及艳后)、娜芙蒂蒂(阿肯那顿的大王后)和哈特谢普苏特(埃及「武则天」)。

近代由于在阿斯旺兴建水坝,联合国筹钱将阿布辛贝勒神庙和小庙搬离到比原地高 200 米处。

频繁的战争、大兴土木,造就了巨大的国库开销,加大了国力下降。在拉美西斯二世死后,埃及就立刻开始走下坡路。
第二十王朝的祭司当权
过了几任法老后,到了第二十王朝第二任法老拉美西斯三世的统治。他抵抗了几次地中海和利比亚的入侵,治下还出现了人类历史上第一次有记录的劳工罢工。他的一个妃子还曾试图毒杀他,最后是失败了。
拉美西斯五世,土地和财政基本就已经被阿蒙神庙的祭司所控制了。
拉美西斯六世在建造坟墓时无意间将图坦卡蒙坟墓埋在了地下,避免了其日后被盗掘。
第二十王朝,古埃及陷入内忧外患,尼罗河水位下降、内政动乱、法老坟墓被盗、官员腐败,又丢了叙利亚和巴勒斯坦,最后法老基本就没有统一埃及的权力了。
包含十八王朝到二十王朝,共三个王朝,20 / 31。
拉美西斯十一世死后,结束二十王朝,斯门代斯一世(Smendes I)开创二十一王朝,然而此时法老权力已经极弱,基本被赶到下埃及去了,上埃及和中埃及地区则是由底比斯阿蒙神庙的大祭司们所控制。
利比亚人的二十二、二十三、二十四王朝
之前二十王朝已经在尼罗河三角洲定居的利比亚人,在舍顺克一世(Shoshenq I)统领下统一埃及,创立二十二王朝,这里的法老已经不是本土埃及人了。然后二十三王朝二十四王朝,王室和内政仍然比较动荡,南方起源于库施(kush)的努比亚王国趁乱北上把整个埃及打了下来,赶走了利比亚人,建立二十五王朝。
努比亚人的二十五王朝
努比亚人重新恢复了古埃及的的宗教传统,修复和建造了不少寺庙和纪念碑,还在家乡(位于现在的苏丹)重新建造起金字塔来。

包含二十一王朝到二十五王朝,共五个王朝,25 / 31。
古埃及晚期 / 波斯帝国时期(Late Period, BC664 - BC332)
之后西亚的亚述人开始入侵古埃及,努比亚人不敌,向南退回努比亚。亚述人可能对占着古埃及没有兴趣,在洗劫一番后退了回去,扶植了普萨美提克一世(Psammetichus I)作为法老。
古埃及本土最后的荣光,二十六王朝
之后,普萨美提克一世趁亚述帝国忙于战乱,联合古希腊的雇佣军,又重新统一了古埃及,建立二十六王朝,恢复了繁荣稳定。之后亚述被内部独立的新巴比伦帝国推翻,普萨美提克一世也曾想恢复西亚的霸权,但被尼布甲尼撒二世(Nebuchadnezzar II)统治的新巴比伦帝国打了回来。
那个古埃及法老用婴儿做实验,实验听不到别人说话怎么学语言的故事,就是普萨美提克一世的故事,记录在希罗多德写的书「历史」第二卷中。

然而二十六王朝已经是最后一个埃及本土王朝了。更东边的波斯阿契美尼德帝国(波斯第一帝国)灭了新巴比伦帝国,接着吞并了古埃及,波斯国王冈比西斯二世(Cambyses II)成了法老,称为二十七王朝。
之后二十六王朝后裔推翻波斯的统治,先后建立短暂的二十八、二十九、三十王朝。
然后波斯人再次征服古埃及,是为三十一王朝。
包含二十六王朝到三十一王朝,共六个王朝,31 / 31。
马其顿的亚历山大解放埃及 -> 托勒密王朝(Macedonian and Ptolemaic Egypt, BC332 - BC30)
埃及解放者,亚历山大
当无人不知的亚历山大击溃波斯大军并来到埃及的时候,根本没有遇到什么抵抗,埃及当地的波斯管理者就直接将埃及献给他了,埃及人民还视其为埃及的解放者。
亚历山大尊重当地信仰,去绿洲朝圣得到神谕。神谕宣称他是阿蒙的儿子。实际上就是得到了祭司等有权势的人的承认。他成立了一个新的希腊城市名为亚历山大(他到哪就在哪建亚历山大城),并任命希腊人——而不是埃及人——作为高官。
亚历山大没有在埃及待很久,就去征服其他地方了,从此再没有回来过。他的部下托勒密留在埃及统治,并从亚历山大死后分崩离析的亚历山大帝国中独立出来,创立托勒密王朝统治了近三百年。
希腊法老,托勒密王朝
托勒密王朝中,男性都叫托勒密(Ptolemy),女性一般叫克利奥帕特拉(Cleopatra)、贝勒尼基(Berenice)和阿尔西诺伊(Arsinoe),因此所有统治者都是这四个名字的加几世这样的称呼。最为人知的就是末代法老,埃及艳后,克利奥帕特拉七世。
托勒密王朝没有使用希腊文明取代埃及文明,反而扶持其延续,修建埃及风格的神庙,维护传统宗教仪式。当然也带来了希腊文明的影响,这个时期很多文艺作品都有两个文明融合的风格。
罗塞塔石碑,托勒密五世诏书
罗塞塔石碑本来并不是什么比较特别的石碑,只是托勒密五世加冕一周内纪念所制,但碑上同时使用了三种语言,分别是圣书体(埃及象形文字)、埃及草书(世俗体)和古希腊文,令后世学者可以做参考比对,通过古希腊文来解读圣书体,从而使这块石碑无比珍贵,也因此罗塞塔石碑在现代也被引申为「暗喻」、「翻译」和「关键线索」等的含义。

艳后与凯撒
克利奥帕特拉七世是托勒密王朝中第一个学会埃及语并接受埃及信仰和埃及神明的人,这是其他王室成员所拒绝的事(想想罗塞塔石碑还需要古希腊文书写)。她早年在就政治上活跃,应该算是被迫和托勒密十三世(同父异母弟弟)结婚以一同统治埃及。但之后两人发生冲突,艳后被迫流亡叙利亚,招兵买马打算反攻托勒密十三世。
此时罗马内部也正在争斗,凯撒打败了庞培,后者被迫跑到埃及。而托勒密十三世可能希望寻求凯撒支持而擅自将凯撒老对手庞培暗杀了,在凯撒追到埃及时献上庞培的头颅。这可能令凯撒十分不满,因为庞培是他的劲敌、女婿,也是罗马执政官,不应该被异国人杀死。
克利奥帕特拉七世可能看准了这个机会潜回埃及,并将自己献给凯撒,做他的情人,取得凯撒的支持。之后凯撒对埃及统治者的仲裁,是克利奥帕特拉七世上位。
传说当时克利奥帕特拉把自己伸直,用毯子卷起来包覆其中,命人抬着进入王宫,这时克利奥帕特拉年仅21岁,凯撒52岁。
维基百科
托勒密十三世当然十分不满,率军围攻亚历山大城内罗马军。凯撒等到增援到来,脱围之后在尼罗河战役打败托勒密十三世,随后另立了托勒密十四世(仍旧是艳后的弟弟)和艳后结婚统治埃及。艳后虽然名义上嫁给托勒密十四世,但是实际上却和凯撒相好,还生了一个孩子托勒密·凯撒。
BC46,艳后来到罗马,遭到罗马人民的厌恶,因为凯撒已婚,而她和凯撒关系暧昧。但凯撒不愧为独裁者,完全罔顾旁人,甚至为艳后制作黄金雕像,和罗马人先祖维纳斯神像一起摆放。在凯撒被刺后,艳后还留在罗马,可能是希望自己儿子继承凯撒。但是凯撒大概没有承认这个儿子,而是在遗嘱另立他的养子屋大维作为继承人。于是她回到埃及,毒死了托勒密十四世,与其儿子共同统治埃及。
艳后与安东尼
安东尼是凯撒生前最重要的军队指挥官。凯撒被刺后,他和屋大维解决了反凯撒势力。之后在埃及传唤艳后的时候也应该是被迷住了,和她在 BC41 到 BC40 年度过了一段时光。接着安东尼离开了埃及,艳后不久后生下一男一女双胞胎,相信就是安东尼的儿女。
安东尼和屋大维从 BC41 年开始就不和,因为安东尼妻子发起了和屋大维对抗的战争。虽然后来妻子突然身亡,安东尼也娶了屋大维的姐姐小屋大薇以维持稳定,但是两人仍然是竞争关系。安东尼把大量土地给予了艳后,屋大维利用这一点宣称其为外国女王而牺牲共和国权利。两人关系持续恶化,安东尼也冷落小屋大薇。之后对安息帝国的战争失利,安东尼回到埃及。BC36 年,艳后又为安东尼生下第二个儿子。
BC34 年赢得对亚美尼亚的战争后,安东尼和艳后在大胜后的举动被屋大维大肆利用,煽动罗马对安东尼的不满,包括艳后以神的名义宣称自己和凯撒的儿子是万王之王,自己则是万王之女王,和安东尼的儿女则分别册封国王等。安东尼更公然向罗马宣称将包括打下亚美尼亚等一部分罗马行省赠予克利奥帕特拉七世。最冒犯屋大维的,是安东尼宣称艳后和凯撒的儿子托勒密·凯撒才应该是凯撒的继承人。
屋大维借机行事向埃及女王宣战,在亚克兴角海战中打败安东尼。安东尼输掉海战的原因可能是因为海军在战事胶着时出现叛逃,安东尼和艳后逃回了埃及,陆军见势也投降屋大维了。
屋大维乘胜追击到埃及,退无可退的安东尼误认为艳后已自杀,用剑刺自己,可能是被带到艳后藏身的坟墓才真正死去。艳后随后也被捕了。
关于克利奥帕特拉七世的死法,无人知道。流传最广的版本是她让毒蛇咬自己而毒发身亡,也有观点认为他是被屋大维下令处死。
她和凯撒的儿子托勒密·凯撒被屋大维处死,从此埃及成为了罗马帝国的行省,托勒密王朝终结,埃及的法老时代也终结了。


罗马统治时期 -> 阿拉伯人入侵
作为罗马帝国行省的埃及,发生的事情属于罗马的历史了,这里不详述。只是 CE264 年的时候,反抗罗马的帕尔米拉女王季诺碧亚征服了埃及使其脱离罗马,并自称埃及女王,说她的家族可追溯到克利奥帕特拉七世。后来罗马也没有战胜她,只能是围城断粮逼其投降。
埃及有一段时间曾被萨珊王朝所占领(CE621 - CE629),拜占庭(东罗马帝国)虽然重新夺回,但十年后阿拉伯帝国入侵的时候,已经无力抵抗,自此埃及伊斯兰化,埃及文明也不复存在。
古埃及神明
古埃及是一个宗教特色很浓的国家,了解其神明系统有助于深入理解古埃及,不过没有兴趣也可不看。
见 古埃及神明 一文。
一些小知识
法老的头冠分两部分,代表上埃及的白色王冠,代表下埃及的红色王冠,一般法老会戴着两个,诏示其为整个埃及的统治者。
古埃及神话中的神明都是兄妹 / 姐弟结合,这可能造成了古埃及王室基本都是近亲结合。如果侧室的儿子登基法老,一般也要娶正室的女儿。统治者可能借此保持所谓的血统纯正。
建造金字塔和神庙的大石头、花岗岩等,很多是从阿斯旺开凿的。
部分参考资料
开放世界埃及篇
古埃及 - 维基百科,自由的百科全书
古埃及历史 - 维基百科,自由的百科全书
阿姨学、古埃及 | 阿姨学词典 Wikia | FANDOM powered by Wikia
History of ancient Egypt - Wikipedia
Prehistoric Egypt - Wikipedia
Early Dynastic Period (Egypt) - Wikipedia
Old Kingdom of Egypt - Wikipedia
First Intermediate Period of Egypt - Wikipedia
Middle Kingdom of Egypt - Wikipedia
Second Intermediate Period of Egypt - Wikipedia
New Kingdom of Egypt - Wikipedia
Third Intermediate Period of Egypt - Wikipedia
Late Period of ancient Egypt - Wikipedia
Ptolemaic Kingdom - Wikipedia
Sasanian Egypt - Wikipedia
First Dynasty of Egypt - Wikipedia
Second Dynasty of Egypt - Wikipedia
Third Dynasty of Egypt - Wikipedia
Fourth Dynasty of Egypt - Wikipedia
Fifth Dynasty of Egypt - Wikipedia
Sixth Dynasty of Egypt - Wikipedia
Seventh Dynasty of Egypt - Wikipedia
Eighth Dynasty of Egypt - Wikipedia
Ninth Dynasty of Egypt - Wikipedia
Tenth Dynasty of Egypt - Wikipedia
Eleventh Dynasty of Egypt - Wikipedia
Eleventh Dynasty of Egypt - Wikipedia
Twelfth Dynasty of Egypt - Wikipedia
Thirteenth Dynasty of Egypt - Wikipedia
Fourteenth Dynasty of Egypt - Wikipedia
Fifteenth Dynasty of Egypt - Wikipedia
Sixteenth Dynasty of Egypt - Wikipedia
Abydos Dynasty - Wikipedia
Seventeenth Dynasty of Egypt - Wikipedia
Eighteenth Dynasty of Egypt - Wikipedia
Nineteenth Dynasty of Egypt - Wikipedia
Twentieth Dynasty of Egypt - Wikipedia
Twenty-first Dynasty of Egypt - Wikipedia
Twenty-second Dynasty of Egypt - Wikipedia
Twenty-third Dynasty of Egypt - Wikipedia
Twenty-fourth Dynasty of Egypt - Wikipedia
Twenty-fifth Dynasty of Egypt - Wikipedia
Twenty-sixth Dynasty of Egypt - Wikipedia
Twenty-eighth Dynasty of Egypt - Wikipedia
Twenty-ninth Dynasty of Egypt - Wikipedia
Thirtieth Dynasty of Egypt - Wikipedia
Argead dynasty - Wikipedia
Ptolemaic Kingdom - Wikipedia
Valley of the Kings - Wikipedia
Giza pyramid complex - Wikipedia
Histories (Herodotus) - Wikipedia
Assyria - Wikipedia
Kingdom of Kush - Wikipedia
Hyksos - Wikipedia
Ramesseum - Wikipedia
Ancient Near East - Wikipedia
Abu Simbel temples - Wikipedia
Egyptian–Hittite peace treaty - Wikipedia
Battle of Kadesh - Wikipedia
Abydos King List - Wikipedia
Abydos, Egypt - Wikipedia
Canaan - Wikipedia
Karnak - Wikipedia
早王朝时期 - 维基百科,自由的百科全书
古王国时期 - 维基百科,自由的百科全书
第一中间时期 - 维基百科,自由的百科全书
中王国时期 - 维基百科,自由的百科全书
第二中间时期 - 维基百科,自由的百科全书
新王国时期 - 维基百科,自由的百科全书
第三中间时期 - 维基百科,自由的百科全书
古埃及晚期 - 维基百科,自由的百科全书
阿契美尼德王朝 - 维基百科,自由的百科全书
托勒密时期 - 维基百科,自由的百科全书
罗马及拜占庭时期 - 维基百科,自由的百科全书
萨珊时期 - 维基百科,自由的百科全书
埃及第一王朝 - 维基百科,自由的百科全书
埃及第二王朝 - 维基百科,自由的百科全书
埃及第三王朝 - 维基百科,自由的百科全书
埃及第四王朝 - 维基百科,自由的百科全书
埃及第五王朝 - 维基百科,自由的百科全书
埃及第六王朝 - 维基百科,自由的百科全书
埃及第七王朝 - 维基百科,自由的百科全书
埃及第十一王朝 - 维基百科,自由的百科全书
埃及第十二王朝 - 维基百科,自由的百科全书
埃及第十三王朝 - 维基百科,自由的百科全书
埃及第十四王朝 - 维基百科,自由的百科全书
埃及第十五王朝 - 维基百科,自由的百科全书
埃及第十六王朝 - 维基百科,自由的百科全书
埃及第十七王朝 - 维基百科,自由的百科全书
埃及第十八王朝 - 维基百科,自由的百科全书
埃及第十九王朝 - 维基百科,自由的百科全书
埃及第二十王朝 - 维基百科,自由的百科全书
埃及第二十一王朝 - 维基百科,自由的百科全书
埃及第二十二王朝 - 维基百科,自由的百科全书
埃及第二十三王朝 - 维基百科,自由的百科全书
埃及第二十四王朝 - 维基百科,自由的百科全书
埃及第二十五王朝 - 维基百科,自由的百科全书
埃及第二十六王朝 - 维基百科,自由的百科全书
埃及第二十七王朝 - 维基百科,自由的百科全书
埃及第二十八王朝 - 维基百科,自由的百科全书
埃及第二十九王朝 - 维基百科,自由的百科全书
埃及第三十王朝 - 维基百科,自由的百科全书
埃及第三十一王朝 - 维基百科,自由的百科全书
古希腊 - 维基百科,自由的百科全书
馬其頓王國 - 维基百科,自由的百科全书
托勒密王朝 - 维基百科,自由的百科全书
波斯 - 维基百科,自由的百科全书
帝王谷 - 维基百科,自由的百科全书
吉萨金字塔群 - 维基百科,自由的百科全书
历史 (希罗多德) - 维基百科,自由的百科全书
亚述 - 维基百科,自由的百科全书
库施 - 维基百科,自由的百科全书
喜克索斯人 - 维基百科,自由的百科全书
拉美西姆 - 维基百科,自由的百科全书
古代近东 - 维基百科,自由的百科全书
阿布辛贝勒神庙 - 维基百科,自由的百科全书
埃及赫梯和约 - 维基百科,自由的百科全书
卡迭石战役 - 维基百科,自由的百科全书
阿拜多斯王表 - 维基百科,自由的百科全书
阿拜多斯 - 维基百科,自由的百科全书
迦南 - 维基百科,自由的百科全书
卡纳克神庙 - 维基百科,自由的百科全书
PDF 版
下载地址
修订记录
2019.05.15
2019.05.20
2019.05.21
2019.05.22
2019.05.23
2019.06.01
]]>